Topics across time: temporal knowledge discovery in urban planning feedback data through machine learning
Design and Planning Lab, Urban Redevelopment Authority of Singapore
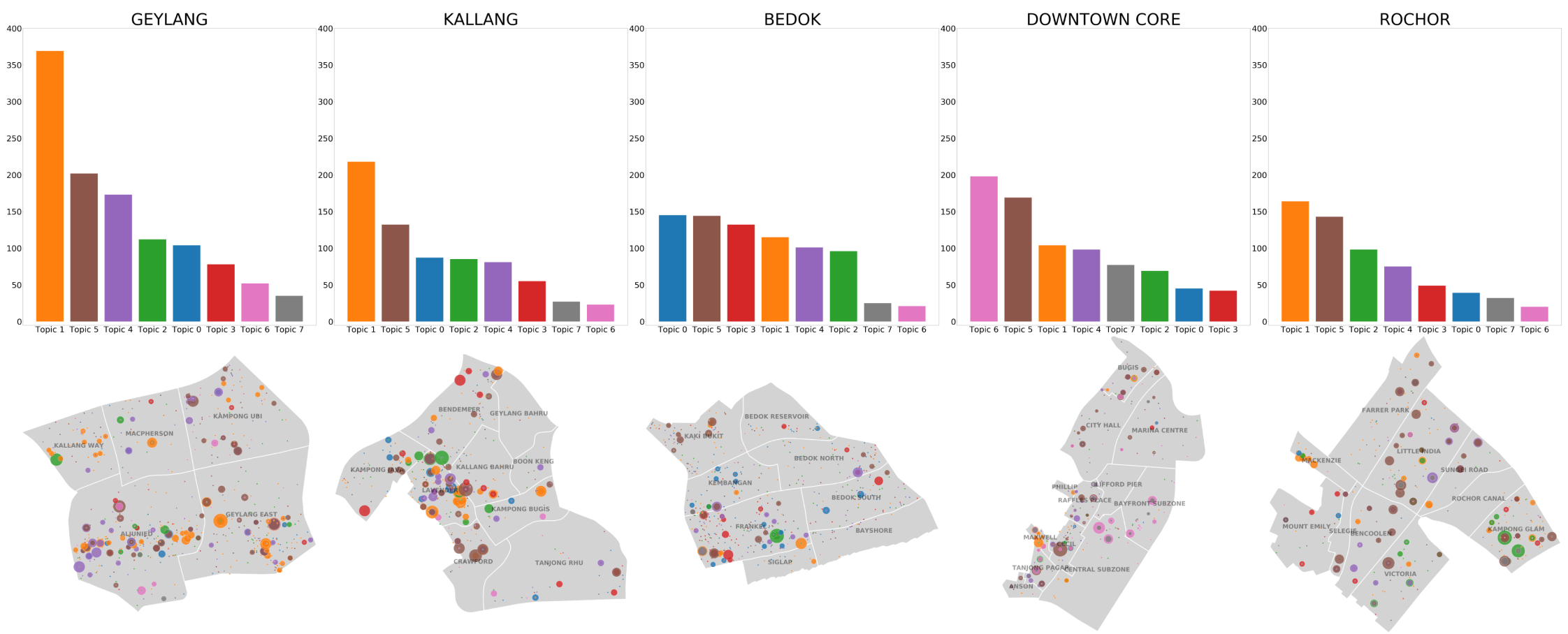
High-quality dialogue between the government and the public is a necessary component of the urban planning process. Data from public surveys, online feedback portals, and social media platforms are standard sources of public opinion on current issues and developments. However, deriving area or issue-specific insights from unstructured text requires planners to read individual messages – a tedious and siloed process that prevents planners from learning across related issues and cases.
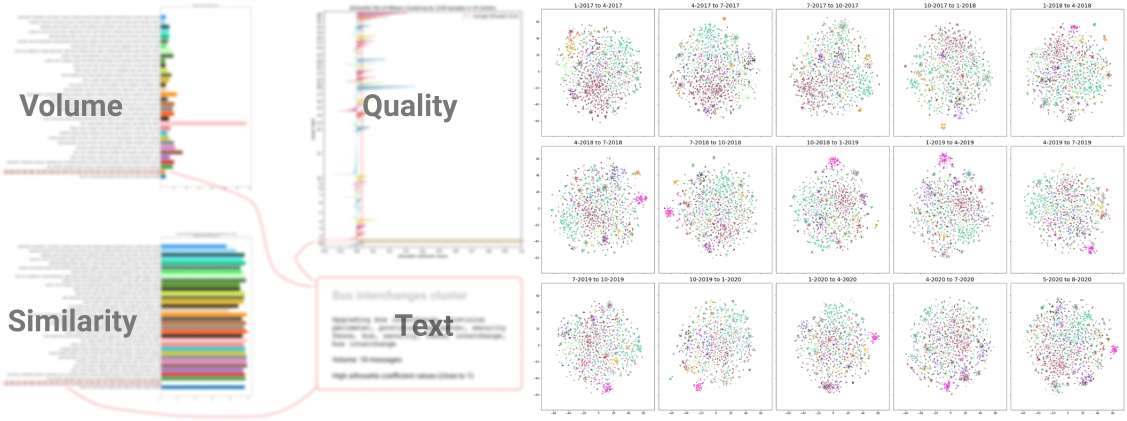
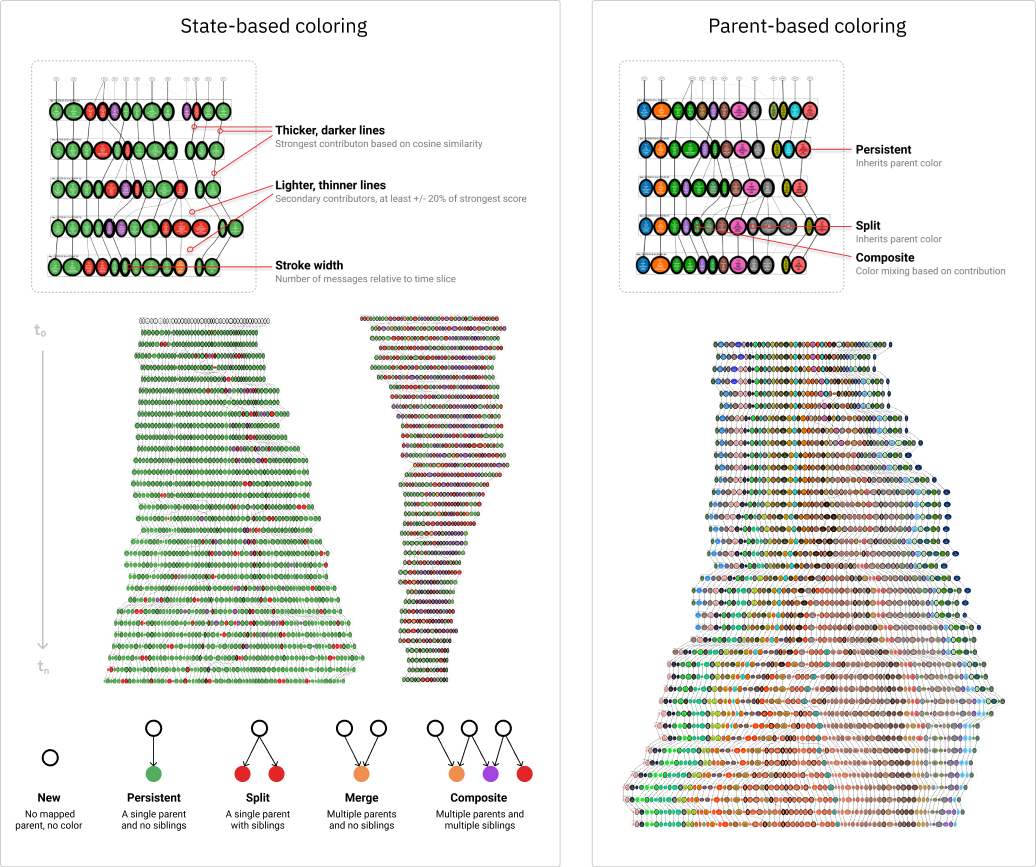
In this project, we interviewed planners to understand the structure of planning departments at URA, their workflows and how they currently use citizen feedback in their day-to-day decision making. Aside from coordinating expectations, meetings and deliverables with the DPL team, I developed a workflow to process unstructured text using natural language processing and machine learning into clusters or ‘topics’, with an emphasis on identifying and assessing the quality of persistent ('evergreen') and 'emergent' topics across time. I explored different metrics for assessing cluster quality and the similarity of clusters to one another temporally, based on the shared occurence of key words. These are reflected in the data visualizations on the next two pages, which were primarily designed by Nazim Ibrahim and involved my input. Both the workflow and data visualizations are currently in the process of being integrated into the ePlanner, an allin- one system of planning knowledge where datasets can be layered onto each other or consulted in detail by planners.
This project served as a precursor to another project on machine-assisted reply generation for urban planning queries. It will be part of the to-be-launched SUTD-URA Centre of Excellence.